9.클러스터드(Clusterd index) 와 논클러스터드(Non-clustered index) 인덱스 차이
인덱싱은 테이블에서 요청한 데이터를 더 빨리 반환한다. 인덱싱이 없으면, SQL서버는 전체 테이블에서 데이터를 검색하야 한다. 인덱싱을 통해 SQL 서버는 인덱스 페이지를 확인하여 책의 내용을 찾을 때와 동일한 작업을 수행한다. 같은 방식으로 테이블의 인덱스를 사용하면 전체 테이블을 스캔하지 않고도 정확한 데이터를 찾을 수 있습니다. SQL에는 두 가지 유형의 인덱싱이 있습니다.
인덱싱 유형
- 클러스터형 인덱스
- 논클러스터형 인덱스
클러스터드 인덱스
- 테이블당 1개씩만 허용된다.
- 물리적으로 행을 재배열한다.
- PK설정 시 그 컬럼은 자동으로 클러스터드 인덱스가 만들어진다.
- 인덱스 자체의 리프 페이지가 곧 데이터이다. 즉 테이블 자체가 인덱스이다.(1. 따로 인덱스 페이지를 만들지 않는다. 2. 클러스터드 인덱스는 논 클러스터드 인덱스 보다 DB용량을 덜 차지한다.)
- 데이터 입력, 수정, 삭제 시 항상 정렬 상태를 유지한다.
- 논클러스터드 인덱스보다 검색속도는 더 빠르다. 하지만 데이터의 입력, 수정, 삭제는 느리다.
- 30% 이내에서 사용해야 좋은 선택도를 가진다.
논 클러스터드 인덱스
- 테이블당 약 240개의 인덱스를 만들 수 있다.
- 인덱스 페이지는 로그파일에 저장된다.
- 레코드의 원본이 정렬되지 않고, 인덱스 페이지만 정렬된다. (데이터의 복사본)
- 인덱스 자체의 리프 페이지는 데이터가 아니라 데이터가 위치하는 포인터(RID)이기 때문에 클러스터형 보다 검색속도는 더 느리지만, 입력, 수정, 삭제는 더 빠르다.
- 인덱스를 생성할 때 데이터 페이지는 그냥 둔 상태에서 별도의 인덱스 페이지를 따로 만들기 때문에 용량을 더 차지한다.
- 3% 이내에서 사용해야 좋은 선택도를 가진다.
쉽게 말해 클러스터드 인덱스는 페이지를 알기 때문에 바로 그 페이지를 펴는 것이고, 논 클러스터드 인덱스는 뒤에 인덱스 페이지에서 찾고자 하는 내용의 페이지를 찾고 그 페이지로 이동하는 것과 같다.
CREATE TABLE clusterdT
(
id int NOT NULL,
value varchar(20) NOT NULL
);
INSERT INTO clusterdT VALUES (17,'indexTest1');
INSERT INTO clusterdT VALUES (15,'indexTest15');
INSERT INTO clusterdT VALUES (7,'indexTest7');
INSERT INTO clusterdT VALUES (8,'indexTest8');
INSERT INTO clusterdT VALUES (4,'indexTest4');
INSERT INTO clusterdT VALUES (2,'indexTest2');
INSERT INTO clusterdT VALUES (3,'indexTest3');
INSERT INTO clusterdT VALUES (11,'indexTest7');
INSERT INTO clusterdT VALUES (9,'indexTest8');
INSERT INTO clusterdT VALUES (14,'indexTest14');
INSERT INTO clusterdT VALUES (5,'indexTest5');
INSERT INTO clusterdT VALUES (10,'indexTes10');
INSERT INTO clusterdT VALUES (13,'indexTest13');
INSERT INTO clusterdT VALUES (6,'indexTest6');
INSERT INTO clusterdT VALUES (12,'indexTest12');
INSERT INTO clusterdT VALUES (16,'indexTest18');
INSERT INTO clusterdT VALUES (1,'indexTest17');
INSERT INTO clusterdT VALUES (18,'indexTest16');
INSERT INTO clusterdT VALUES (19,'indexTest19');
SELECT * FROM clusterdT;
셀렉트 시 입력한 그대로 출력이 된다. 여기서 기본키를 추가를 하면
ALTER TABLE clusterdT ADD PRIMARY KEY(id);
SELECT * FROM clusterdT;
id 별로 정렬이 되어 나오는 것을 볼 수 있다. 기본키를 지우면 어떻게 될까?


기본키를 제거후에도 데이터는 정렬되어 있는 모습을 볼 수 있다. 기본키를 지정할 때 데이터를 재정렬 한다는 것을 알 수 있다.
클러스터드 인덱스를 구성하려면 행 데이터를 해당 열로 정렬한 후에 루트 페이지를 만들게 됩니다. 즉 데이터 페이지는 리프 노드와 같은 것을 확인할 수 있습니다.

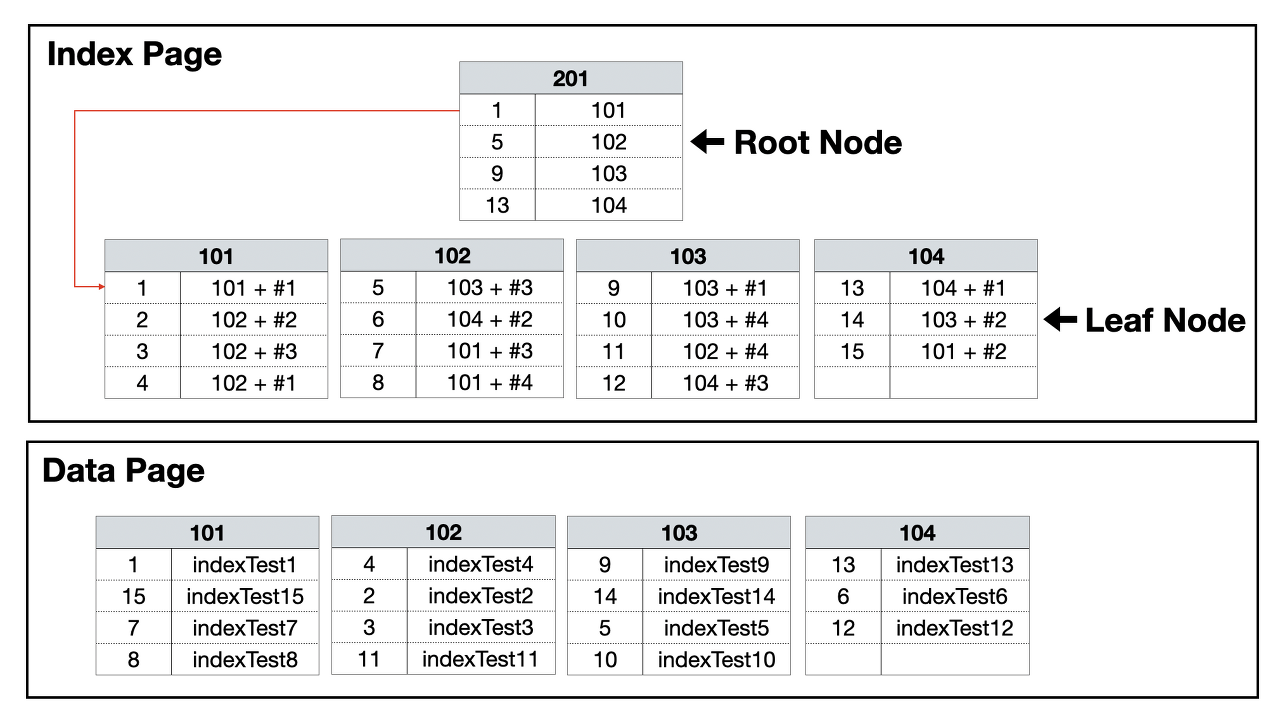
논 클러스터드 인덱스는 데이터 페이지를 건들지 않고, 별도의 장소에 인덱스 페이지를 생성합니다. 우선 인덱스 페이지를 리프 페이지에 인덱스 로 구성한 열을 정렬하고 데이터 위치 포인터를 생성합니다. 데이터 위치 포인트는 클러스터형 인덱스와 달리 '페이지 번호 + #오프셋'이 기록되어 바로 데이터 위치를 가리킵니다. indexTest2로 예를 들면 102번 페이지의 두 번째(#2)에 데이터가 있다고 기록하게 됩니다. 그러므로 이 데이터 위치 포인터는 데이터가 위치한 고유한 값이 됩니다.
클러스터드 인덱스 vs 논클러스터드 인덱스
| CLUSTERD INDEX | NON-CULSTERD INDEX |
| 클러스터드 인덱스는 빠르다. | 논클러스터드 인덱스는 느리다. |
| 클러스터드 인덱스는 작업에 필요한 메모리가 작다. | 논클러스터드 인덱스는 작업에 더 많은 메모리가 필요하다. |
| 클러스터드 인덱스는 주요 데이터이다. | 논클러스터드 인덱스의 인덱스는 데이터의 복사본이다. |
| 테이블에는 클러스터드 인덱스가 하나만 있을 수 있다. | 테이블에는 논클러스터드 인덱스가 여러개 있을 수 있다. |
| 클러스터드 인덱스는 디스크에 데이터를 저장하는 고유한 기능이 있다. | 논클러스터드 인덱스에는 디스크에 데이터를 저장하는 고유한 기능이 없다. |
| 클러스터드 인덱스는 데이터가 아닌 블록에 대한 포인터를 저장한다. | 논클러스터드 인덱스는 값과 데이터를 보유하는 실제 행에 대한 포인터를 저장한다. |
| 클러스터드 인덱스에서 리프노드는 실제 데이터 자체이다. | 논클러스터드 인덱스에서 리프노드는 실제 데이터 자체가 아니라 포함된 컬럼만 포함한다. |
| 클러스터드 인덱스에서 클러스터 키는 테이블 내 데이터 순서를 정의한다. | 논클러스터드 인덱스에서 인덱스 키는 인덱스 내 데이터의 순서를 정의한다. |
| 클러스터드 인덱스는 테이블 레코드가 인덱스와 일치하도록 물리적으로 재정렬되는 인덱스 유형이다. | 논클러스터드 인덱스는 인덱스의 논리적 순서가 디스크에 있는 행의 물리적으로 저장된 순서와 일치하지 않는 특수한 유형의 인덱스이다. |